$GME To The Moon: How Much of an Outlier Was Gamestop's January Rise?

Introduction
Between January 13th and January 27th, 2021 the stock price for Gamestop (GME) rose 10x from $31 to $347 dollars. This rise was in part due to increased popularity on the Reddit forum r/wallstreetbets looking to create a short squeeze and because they “liked the stock”. This rapid rise also drew attention of popular media such as CNBC:

However, this post will not try to understand the mechanics of why GME rose or whether it should have risen. What I will try to answer is “how unexpected was its rise” using an array of different forecasting tools. To assess how expected this rise in GME stock is, I’ll be using the following packages:
- Anomalize
- Prophet
- Forecast (auto.arima)
- CausalImpact
From these methods we should get a good idea of just how unexpected this rise was. The method for doing this will be using historical price data through January 21st to predict the Gamestop stock price for the period of January 22nd, through February 4th and looking at the mean average percent error (MAPE1) to quantify the amount of unexpectedness.
As a reminder the MAPE is calculated as: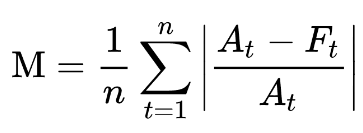
where A is the actual and F is the forecasted value.
Peer Sets
While I can look at the GME time-series and know that its an outlier relative to past performance maybe something in early January caused all video games related stocks to increase. The peer set that I will look at using as external regressors are:
- Nintendo (NTDOF) - Maker of the Switch System
- Sony (SONY) - Maker of the Playstation System
- Microsoft (MSFT) - Maker of the XBox System
Data
I’ll be using the stock prices for these four stocks from 1/1/2016 through 2/22/2021 for this analysis and I will use the tidyquant package to get this data through the tq_get() function.
library(tidyquant) #Get Stock Data
library(tidyverse) #Data Manipulation
library(lubridate) #Date Manipulation### Make Data Weekly
dt <- tq_get(c('GME', 'SONY', 'NTDOF', 'MSFT'),
get='stock.prices',
from = '2016-01-01',
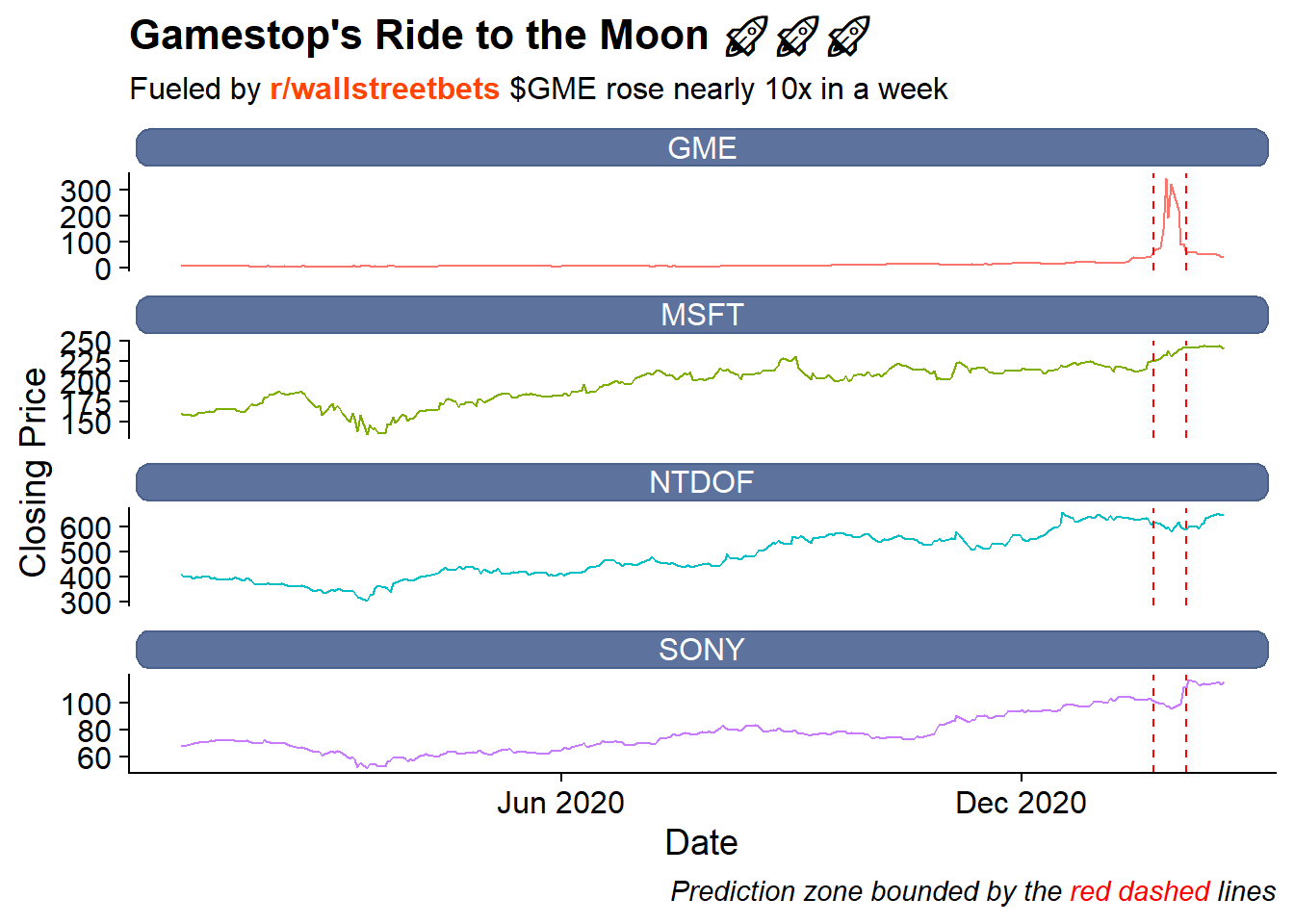
to = '2021-02-22') With the data pulled we can visualize each of the time-series for the four stocks. While the peer stocks all rose between 2020 and Feb 2021 it does appear that Gamestop truly “goes to the moon” above and beyond the peer stocks.
dt %>%
filter(ymd(date) >= ymd(20200101)) %>%
ggplot(aes(x = date, y=close, color = symbol, group = symbol)) +
geom_line() +
geom_vline(xintercept = ymd(20210122), lty = 2, color = 'red') +
geom_vline(xintercept = ymd(20210204), lty = 2, color = 'red') +
labs(x = "Date", y = "Closing Price", title = "Gamestop's Ride to the Moon 🚀🚀🚀",
subtitle = "Fueled by <span style='color:#ff4500'><b>r/wallstreetbets</b></span> $GME rose nearly 10x in a week",
caption = "<i>Prediction zone bounded by the <span style='color:red'>red dashed</span> lines</i>"
) +
scale_color_discrete(guide = 'none') +
scale_x_date(date_breaks = "6 months", date_labels = "%b %Y") +
facet_wrap(~symbol, ncol = 1, scales = "free_y") +
cowplot::theme_cowplot() +
theme(
plot.title = ggtext::element_markdown(),
plot.subtitle = ggtext::element_markdown(),
plot.caption = ggtext::element_markdown(),
strip.background = element_blank(),
strip.text = ggtext::element_textbox(
size = 12,
color = "white", fill = "#5D729D", box.color = "#4A618C",
halign = 0.5, linetype = 1, r = unit(5, "pt"), width = unit(1, "npc"),
padding = margin(2, 0, 1, 0), margin = margin(3, 3, 3, 3)
)
)
Anomalize
anomalize is a package developed by Business Science to enable tidy anomaly detection. This package has three primarily functions:
time_decompose()- which separates the data into its componentsanomalize()- which runs anomaly detection on the remainder componenttime_recompose()- recomposes the data to create limits around the “normal” data.
The package also provides two options for calculating the remainders, STL and Twitter. The STL method does seasonal decomposition through loess while the Twitter method does seasonal decomposition through medians. Additionally there are two options for calculating the anomalies from the remainders, IQR and GESD.
As for which methods to choose, a talk from Catherine Zhou summarizes the choice as:
- Twitter + GESD is better for highly seasonal data
- STL + IQR better if seasonality isn’t a factor.
More details on these methods are available in the anomalize methods vignettes.
Since all of these stocks benefit from increases in holiday sales I’ll use STL + IQR. Unfortunately, anomalize (to my knowledge) cannot handle covariates, so I’ll only be checking for anomalies for the Gamestop stock. Although I’ll add other regressors in the other packages.
library(anomalize)
anomalize_dt <- dt %>%
filter(symbol == 'GME') %>%
# Merge keeps all of the original data in the decomposition
time_decompose(close, method = 'stl', merge = T, trend = "1 year") %>%
anomalize(remainder, method = "iqr") %>%
time_recompose() %>%
filter(between(date, ymd(20210122), ymd(20210204)))Looking at our prediction window returns:
predictions_anomalize <- anomalize_dt %>%
transmute(date, actual = close, predicted = trend + season,
normal_lower = recomposed_l1, normal_upper = recomposed_l2,
residual = remainder, anomaly)
knitr::kable(predictions_anomalize, digits = 2)| date | actual | predicted | normal_lower | normal_upper | residual | anomaly |
|---|---|---|---|---|---|---|
| 2021-01-22 | 65.01 | 16.97 | 10.08 | 23.68 | 48.04 | Yes |
| 2021-01-25 | 76.79 | 17.06 | 10.17 | 23.77 | 59.73 | Yes |
| 2021-01-26 | 147.98 | 17.15 | 10.26 | 23.86 | 130.83 | Yes |
| 2021-01-27 | 347.51 | 17.27 | 10.37 | 23.98 | 330.24 | Yes |
| 2021-01-28 | 193.60 | 17.36 | 10.47 | 24.07 | 176.24 | Yes |
| 2021-01-29 | 325.00 | 17.44 | 10.54 | 24.15 | 307.56 | Yes |
| 2021-02-01 | 225.00 | 17.53 | 10.64 | 24.24 | 207.47 | Yes |
| 2021-02-02 | 90.00 | 17.62 | 10.73 | 24.33 | 72.38 | Yes |
| 2021-02-03 | 92.41 | 17.74 | 10.84 | 24.45 | 74.67 | Yes |
| 2021-02-04 | 53.50 | 17.83 | 10.94 | 24.54 | 35.67 | Yes |
So anomalize correctly identified all dates as anomalies vs what was expected. Now I can calculate the MAPE as 84.09% which means that only 16% of Gamestop’s stock movement was predicted.
Prophet
Prophet is a forecasting library that was developed by Facebook. To calculate the MAPE, I will fit the prophet model to the data before the prediction period and then predict for the data in our prediction period (post). Prophet does allow for the addition of other regressors so I will run two version of the model. The first will just be on the Gamestop time series and the second will bring in the Sony, Nintendo, and Microsoft regressors.
Data Processing
Currently, the data is in a tidy format where all symbols are in a separate row. In order to use them in prophet (and in future packages), I need to have the data in a format where each row is a date and all of the symbols are separate columns. Additionally, to be used in prophet the data must have a ds column for for the date and a y column for the time series being projected. The following code block will split into the pre-period and the prediction period as well as rename the GME series to y and date to ds.
prep_data <- dt %>%
select(date, symbol, close) %>%
pivot_wider(names_from = 'symbol', values_from = 'close') %>%
rename(y = GME, ds = date)
pre <- prep_data %>% filter(ds <= ymd(20210121))
pred <- prep_data %>% filter(between(ds, ymd(20210122), ymd(20210204)))Model 1: Only the Gamestop Time Series
library(prophet)
#Build the Model
model_no_regressors <- prophet(pre)
#Predict on the Future Data
model_no_regressors_pred <- predict(model_no_regressors, pred)We can look at the predicted results and the residuals by joining the actual data back to the predicted data:
predictions_prophet_no_reg <- model_no_regressors_pred %>%
inner_join(pred %>% select(ds, y), by = "ds") %>%
transmute(ds, actual = y, predicted = yhat, lower = yhat_lower,
upper = yhat_upper, residual = y-yhat)
knitr::kable(predictions_prophet_no_reg, digits = 2)| ds | actual | predicted | lower | upper | residual |
|---|---|---|---|---|---|
| 2021-01-22 | 65.01 | 17.74 | 14.91 | 20.59 | 47.27 |
| 2021-01-25 | 76.79 | 17.31 | 14.56 | 20.15 | 59.48 |
| 2021-01-26 | 147.98 | 17.14 | 14.13 | 19.90 | 130.84 |
| 2021-01-27 | 347.51 | 17.03 | 14.29 | 19.93 | 330.48 |
| 2021-01-28 | 193.60 | 16.89 | 13.89 | 19.31 | 176.71 |
| 2021-01-29 | 325.00 | 16.55 | 13.99 | 19.29 | 308.45 |
| 2021-02-01 | 225.00 | 16.24 | 13.43 | 19.01 | 208.76 |
| 2021-02-02 | 90.00 | 16.16 | 13.66 | 18.90 | 73.84 |
| 2021-02-03 | 92.41 | 16.14 | 13.46 | 18.83 | 76.27 |
| 2021-02-04 | 53.50 | 16.11 | 13.47 | 18.79 | 37.39 |
From this I can calculate the MAPE as 84.71% again indicatoring that only 16% of the movement was “expected”.
Model 2: Gamestop + Regressors
To run a prophet model with regressions the syntax is a little bit different as rather than pass a dataset into the prophet() function, I’ll need to start with the prophet() function, add the regressors and then pass the data into a fit_prophet() function to actually fit the model.
# Initialize Model
prophet_reg <- prophet()
#Add Regressors
prophet_reg <- add_regressor(prophet_reg, 'MSFT')
prophet_reg <- add_regressor(prophet_reg, 'SONY')
prophet_reg <- add_regressor(prophet_reg, 'NTDOF')
#Fit Model
prophet_reg <- fit.prophet(prophet_reg, pre)
# Predict on Future Data
prophet_reg_pred <- predict(prophet_reg, pred)Then looking at the predictions:
predictions_prophet_reg <- prophet_reg_pred %>%
inner_join(pred %>% select(ds, y), by = "ds") %>%
transmute(ds, actual = y, predicted = yhat, lower = yhat_lower,
upper = yhat_upper, residual = y-yhat)
knitr::kable(predictions_prophet_reg, digits = 2)| ds | actual | predicted | lower | upper | residual |
|---|---|---|---|---|---|
| 2021-01-22 | 65.01 | 20.32 | 17.95 | 22.78 | 44.69 |
| 2021-01-25 | 76.79 | 19.17 | 16.66 | 21.71 | 57.62 |
| 2021-01-26 | 147.98 | 18.95 | 16.22 | 21.39 | 129.03 |
| 2021-01-27 | 347.51 | 18.07 | 15.52 | 20.69 | 329.44 |
| 2021-01-28 | 193.60 | 17.47 | 14.93 | 19.74 | 176.13 |
| 2021-01-29 | 325.00 | 17.61 | 15.09 | 19.98 | 307.39 |
| 2021-02-01 | 225.00 | 17.22 | 14.67 | 19.65 | 207.78 |
| 2021-02-02 | 90.00 | 17.61 | 14.97 | 20.02 | 72.39 |
| 2021-02-03 | 92.41 | 21.18 | 18.40 | 23.63 | 71.23 |
| 2021-02-04 | 53.50 | 21.25 | 18.75 | 23.61 | 32.25 |
which gives us a MAPE of 82.14%. The addition of the external regressors make the forecast errors slightly lower. Now the movement is 18% expected.
Auto.Arima
auto.arima() is a function within the forecast package that algorithmically determines the proper specification for an ARIMA (auto-regressive integrated moving average) model. The basic version of auto-arima fits on a univariate series which I will do first, and then I’ll use external regressors similar to what was done with Prophet.
Model 1: Only Gamestop Time Series
library(forecast)
# Fit auto arima model
auto_arima_model <- auto.arima(pre$y)The function returns an ARIMA(1, 2, 2) model. The forecast() function is then used for use the model to forecast into the future.
# Forecast 10 Periods Ahead
auto_arima_pred <- forecast(auto_arima_model, 10)Then as with the earlier models I can look at the predictions vs. the actuals. The forecast object returns a list where I can pull out the forecast from the “mean” item and the predicted bound using lower and upper. The list contains intervals for both 80% and 95% so the [, 2] pulls the 95% intervals.
predictions_auto_arima <- pred %>%
bind_cols(
tibble(
predicted = auto_arima_pred$mean %>% as.numeric(),
lower = auto_arima_pred$lower[, 2] %>% as.numeric(),
upper = auto_arima_pred$upper[, 2] %>% as.numeric()
)
) %>%
transmute(
ds, actual = y, predicted, lower, upper, residuals = y - predicted
)
knitr::kable(predictions_auto_arima, digits = 2)| ds | actual | predicted | lower | upper | residuals |
|---|---|---|---|---|---|
| 2021-01-22 | 65.01 | 43.71 | 42.35 | 45.07 | 21.30 |
| 2021-01-25 | 76.79 | 44.37 | 42.41 | 46.32 | 32.42 |
| 2021-01-26 | 147.98 | 45.04 | 42.62 | 47.47 | 102.94 |
| 2021-01-27 | 347.51 | 45.70 | 42.87 | 48.54 | 301.81 |
| 2021-01-28 | 193.60 | 46.38 | 43.17 | 49.59 | 147.22 |
| 2021-01-29 | 325.00 | 47.04 | 43.48 | 50.60 | 277.96 |
| 2021-02-01 | 225.00 | 47.72 | 43.82 | 51.61 | 177.28 |
| 2021-02-02 | 90.00 | 48.37 | 44.16 | 52.59 | 41.63 |
| 2021-02-03 | 92.41 | 49.05 | 44.53 | 53.57 | 43.36 |
| 2021-02-04 | 53.50 | 49.71 | 44.89 | 54.53 | 3.79 |
This gives a MAPE of 57.20%, which is much better than the prior methods.
Adding in External Regressors
auto.arima can also take into account external regressors through the xreg parameter. Its a little trickier to implement since the regressors need to be in a Matrix. But as usual, StackOverflow comes through with a solution. In this case its from the package author himself!
# Create Matrix of External Regressors
xreg <- model.matrix(~ SONY + NTDOF + MSFT - 1, data = pre)
# Fit ARIMA Model
auto_arima_reg <- auto.arima(pre$y, xreg = xreg)
# Create Matrix of Extenral Regressors for Forecasting
xreg_pred <- model.matrix(~ SONY + NTDOF + MSFT - 1, data = pred)
# Forecast with External Regressors
auto_arima_reg_fcst <- forecast(auto_arima_reg, h = 10, xreg = xreg_pred)predictions_auto_arima_reg <- pred %>%
bind_cols(
tibble(
predicted = auto_arima_reg_fcst$mean %>% as.numeric(),
lower = auto_arima_reg_fcst$lower[, 2] %>% as.numeric(),
upper = auto_arima_reg_fcst$upper[, 2] %>% as.numeric()
)
) %>%
transmute(
ds, actual = y, predicted, lower, upper, residuals = y - predicted
)
knitr::kable(predictions_auto_arima_reg, digits = 2)| ds | actual | predicted | lower | upper | residuals |
|---|---|---|---|---|---|
| 2021-01-22 | 65.01 | 43.70 | 42.34 | 45.06 | 21.31 |
| 2021-01-25 | 76.79 | 44.37 | 42.42 | 46.32 | 32.42 |
| 2021-01-26 | 147.98 | 45.10 | 42.69 | 47.52 | 102.88 |
| 2021-01-27 | 347.51 | 45.69 | 42.86 | 48.52 | 301.82 |
| 2021-01-28 | 193.60 | 46.51 | 43.31 | 49.71 | 147.09 |
| 2021-01-29 | 325.00 | 46.96 | 43.41 | 50.51 | 278.04 |
| 2021-02-01 | 225.00 | 47.88 | 44.00 | 51.76 | 177.12 |
| 2021-02-02 | 90.00 | 48.53 | 44.33 | 52.73 | 41.47 |
| 2021-02-03 | 92.41 | 49.55 | 45.04 | 54.06 | 42.86 |
| 2021-02-04 | 53.50 | 50.17 | 45.36 | 54.99 | 3.33 |
This gives a MAPE of 57.03%. Again the addition of external regressors only makes things slightly better.
CausalImpact
CausalImpact is a package developed by Google to measure the causal impact of an intervention on a time series. The package uses a Bayesian Structural Time-Series model to estimate a counter-factual of how a response would have evolved without the intervention. This package works by comparing a time-series of interest to a set of control time series and uses the relationships pre-intervention to predict the counterfactual.
CasualInference also will require some data preparation as it requires a zoo object as an input. But I can largely leverage the prep_data data set created in the prophet section as CausalInference only requires that the field of interest is in the first column. The construction of the zoo object take in the data and the date index as its two parameters.
Then for running the causal impact analysis, I pass in the zoo data set and specific what are the pre-period and the post-period. The model.args options of model.args = list(nseasons = 5, season.duration = 1) adds day of week seasonality by specifying that there are 5 periods to a seasonal component that each point represents 1 period of a season. For another example to add day of week seasonality to data with hourly granularity then I would specify nseasons=7 and season.duration=24 to say that there are 7 period in a season and 24 data points in a period.
library(CausalImpact)
#Create Zoo Object
dt_ci <- zoo(prep_data %>% dplyr::select(-ds), prep_data$ds)
#Run Causal Impact
ci <- CausalImpact(dt_ci,
pre.period = c(as.Date('2020-05-03'), as.Date('2021-01-21')),
post.period = c(as.Date('2021-01-22'), as.Date('2021-02-04')),
model.args = list(nseasons = 5, season.duration = 1)
)To get the information about the predictions, I can pull them out of the series attribute within the ci object. While not being used in this analysis, the summary() and plot() functions are very useful. And the option for summary(ci, "report") is interesting in that it gives a full paragraph description of the results.
predictions_causal_inference <- ci$series %>%
as_tibble(rownames = 'ds') %>%
filter(between(ymd(ds), ymd(20210122), ymd(20210204))) %>%
transmute(ds, actual = response, predicted = point.pred,
lower = point.pred.lower, upper = point.pred.upper,
residual = point.effect)
knitr::kable(predictions_causal_inference, digits = 2)| ds | actual | predicted | lower | upper | residual |
|---|---|---|---|---|---|
| 2021-01-22 | 65.01 | 39.17 | 34.08 | 44.21 | 25.84 |
| 2021-01-25 | 76.79 | 38.40 | 32.58 | 43.85 | 38.39 |
| 2021-01-26 | 147.98 | 38.71 | 33.25 | 44.76 | 109.27 |
| 2021-01-27 | 347.51 | 38.58 | 32.86 | 44.85 | 308.93 |
| 2021-01-28 | 193.60 | 39.06 | 33.24 | 45.83 | 154.54 |
| 2021-01-29 | 325.00 | 39.21 | 32.71 | 45.93 | 285.79 |
| 2021-02-01 | 225.00 | 38.29 | 32.08 | 45.04 | 186.71 |
| 2021-02-02 | 90.00 | 38.60 | 31.59 | 45.92 | 51.40 |
| 2021-02-03 | 92.41 | 38.40 | 31.52 | 45.83 | 54.01 |
| 2021-02-04 | 53.50 | 38.96 | 31.11 | 46.97 | 14.54 |
This would give us a MAPE of 64.60%, which is between the auto.arima models and the other methods.
Conclusion
This post looked at five different mechanisms to forecast what Gamestop’s stock price would be during the period when it spiked. Bringing all of the projections together with the actuals gives us:
all_combined <- bind_rows(
#Actuals
dt %>% filter(symbol == 'GME') %>%
transmute(ds = ymd(date), lbl = 'actuals', y = close),
#Anomalize
predictions_anomalize %>%
transmute(ds = ymd(date), lbl = "Anomalize", y = predicted),
#Prophet Regressors
predictions_prophet_no_reg %>%
transmute(ds = ymd(ds), lbl = "Prophet (No Regressors)", y = predicted),
#Prophet No Regressors
predictions_prophet_reg %>%
transmute(ds = ymd(ds), lbl = "Prophet (w/ Regressors)", y = predicted),
#Auto.Arima (No Regressors)
predictions_auto_arima %>%
transmute(ds = ymd(ds), lbl = "Auto.Arima (No Regressors)", y = predicted),
#Auto.Arima (w/ Regressors)
predictions_auto_arima_reg %>%
transmute(ds = ymd(ds), lbl = "Auto.Arima (w/ Regressors)", y = predicted),
#Causal Inference
predictions_causal_inference %>%
transmute(ds = ymd(ds), lbl = "CausalImpact", y = predicted)
)
all_combined %>%
filter(ds >= '2021-01-18' & ds <= '2021-02-04') %>%
ggplot(aes(x = ds, y = y, color = lbl)) +
geom_line() +
geom_vline(xintercept = ymd(20210122), lty = 2, color = 'darkred') +
geom_vline(xintercept = ymd(20210204), lty = 2, color = 'darkred') +
labs(title = "Comparing GME Price Projections 1/22/21 - 2/4/21",
x = "Date",
y = "GME Closing Price ($)",
color = "") +
scale_x_date(date_breaks = "2 days", date_labels = "%b %d") +
scale_y_log10() +
scale_color_manual(values = wesanderson::wes_palette("Zissou1",
n = 7,
type = 'continuous')) +
cowplot::theme_cowplot() +
theme(
legend.direction = 'horizontal',
legend.position = 'bottom'
) +
guides(color=guide_legend(nrow=3,byrow=TRUE))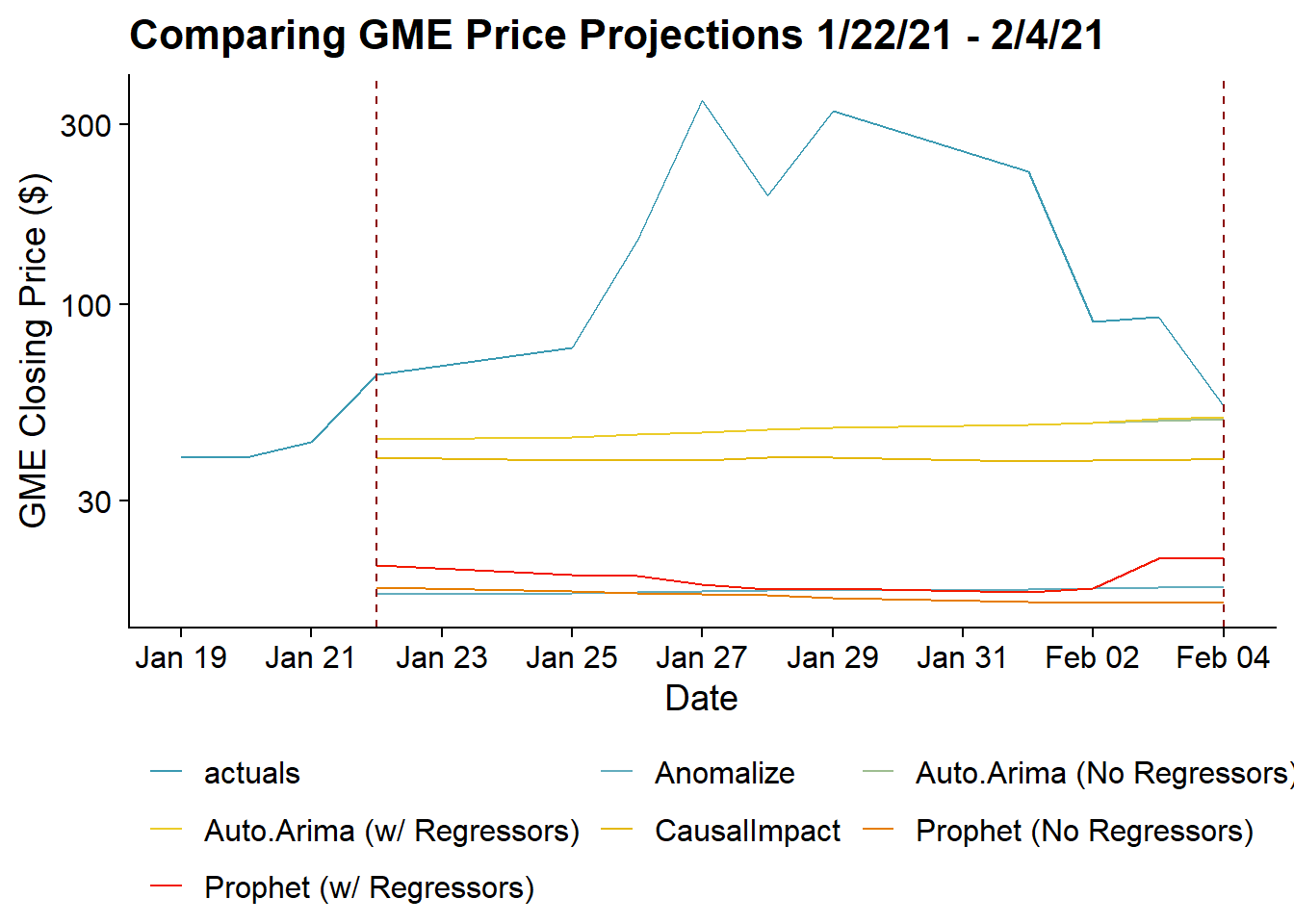
Looking at all the projections together its clear that no forecasting method really saw the massive spike in price coming. Although it looks like the Auto.Arima method comes closest, but potentially more because its started from the highest point rather than any forecast being particularly sensitive.
Looking just at January 27th, the peak of the spike gives the clearest perspective on the difference between the actual and all the projections:
all_combined %>%
filter(ds == '2021-01-27') %>%
ggplot(aes(x = fct_reorder(lbl, y), y = y, fill = lbl)) +
geom_col() +
geom_text(aes(label = y %>% scales::dollar(),
hjust = (y >= 300))) +
labs(x = "Projection Method",
y = "GME Closing Price on Jan 27",
title = "Looking at the Peak of the Spike",
subtitle = "Gamestop Closing Price on January 27, 2021",
fill = "") +
scale_fill_manual(guide = F,
values = wesanderson::wes_palette("Zissou1",
n = 7,
type = 'continuous')) +
scale_y_continuous(label = scales::dollar) +
coord_flip() +
cowplot::theme_cowplot()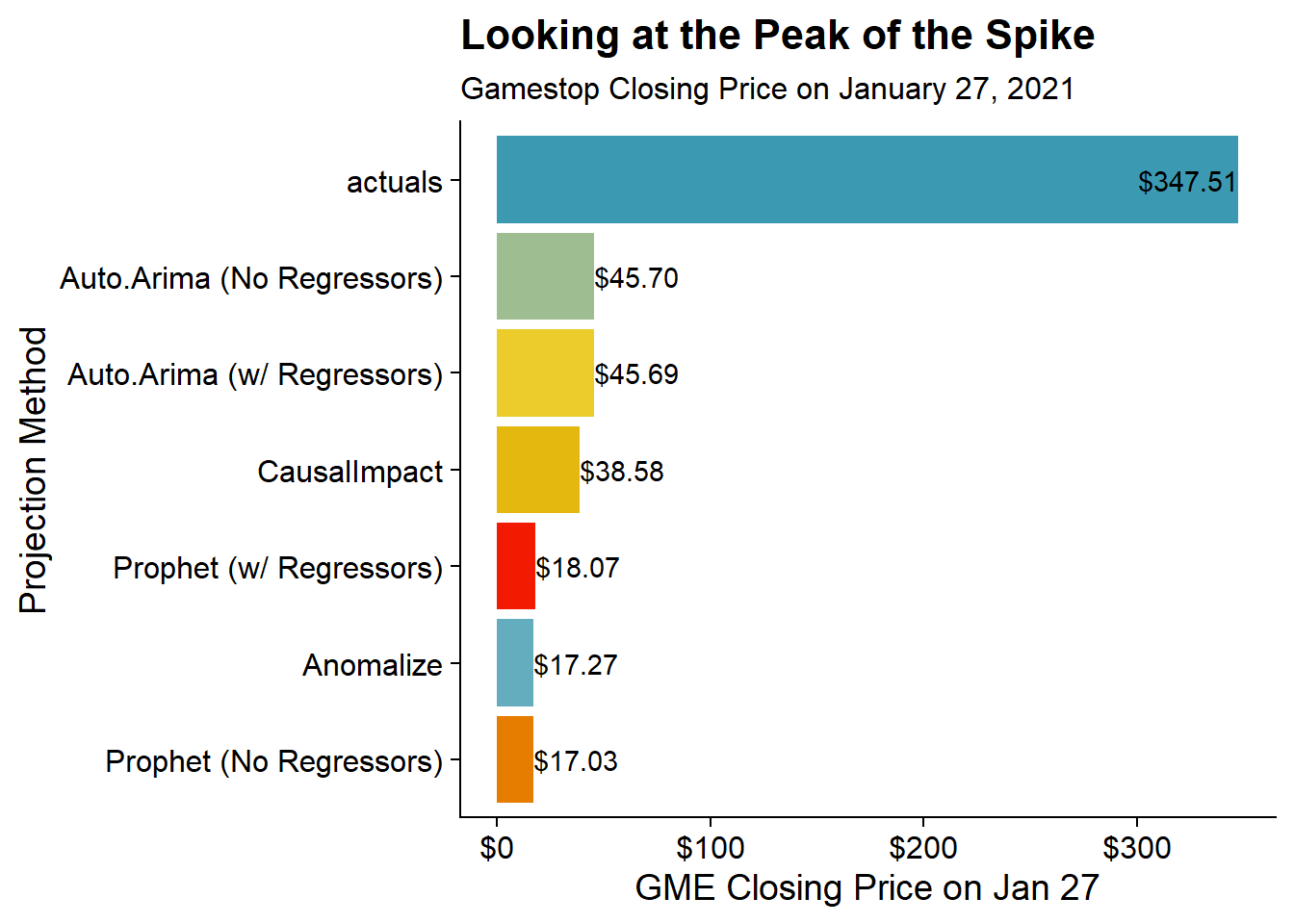 No methodology really comes within $300 of the actual price. To quantify just how unexpected Gamestop’s rise is, I’ll look at the MAPEs for all the forecasting methods.
No methodology really comes within $300 of the actual price. To quantify just how unexpected Gamestop’s rise is, I’ll look at the MAPEs for all the forecasting methods.
format_mape <- function(dt, method){
return(
dt %>%
yardstick::mape(actual, predicted) %>%
transmute(Method = method, MAPE = .estimate %>% scales::percent(scale = 1, accuracy = .01))
)
}
bind_rows(
#Anomalize
format_mape(predictions_anomalize, "Anomalize"),
#Prophet Regressors
format_mape(predictions_prophet_no_reg, "Prophet (No Regressors)"),
#Prophet No Regressors
format_mape(predictions_prophet_reg, "Prophet (w/ Regressors)"),
#Auto.Arima
format_mape(predictions_auto_arima, "Auto.Arima (No Regressors)"),
#Auto.Arima (w/ Rregressors)
format_mape(predictions_auto_arima_reg, "Auto.Arima (w/ Regressors)"),
#Causal Inference
format_mape(predictions_causal_inference, "CausalImpact")
) %>%
knitr::kable(align = c('l', 'r'))| Method | MAPE |
|---|---|
| Anomalize | 84.09% |
| Prophet (No Regressors) | 84.71% |
| Prophet (w/ Regressors) | 82.14% |
| Auto.Arima (No Regressors) | 57.20% |
| Auto.Arima (w/ Regressors) | 57.03% |
| CausalImpact | 64.60% |
Using the MAPE as the measure of “unexpectedness” I would conclude that this outcome 57% to 85% unexpected (although a lot of the accuracy comes less from the models doing a good job of predicting the spike and more from the models being flat and the stock price coming back down). So despite a small rise before the projection period, its clear that Gamestops’s meteoric rise and then fall would a very unexpected event.
Practically, the MAPE function is being calculated using the
yardstickpackage where the format isyardstick::mape(truth, estimate)where truth and estimate are the columns for the actual and predicted values.↩︎